调参经验
03 Apr 2020一、数据
1. 先保证数据质量再去调参
什么是高质量的数据?
高质量数据集应该包括以下特征:
- 类别均衡
- 数据充足
- 数据和标记中有高质量信息
- 数据和标记错误非常小
- 与你的问题相关
2. 怎样获取高质量的数据?
- 尽可能使用公共数据集;
- 寻找可以获取高质量、多样化样本的最佳网站;
- 分析错误并过滤掉与实际问题无关的样本;
- 删除一些过于复杂的图片,这些图片在训练中产生的价值很小,会影响模型的训练效率;
- 收集足够的样本。如果样本不够,应用迁移学习或者数据扩充技术。
- 在对图片进行处理时,要避免裁剪过多,丢失图片信息和过度缩放损失图片的长宽比。
二、调参原则
1. 避免随机改进
首先分析自己模型的弱点,而不是随意地改进,我们需要根据可视化模型误差(表现极差的场景)以及性能参数来确定模型问题。随意做改进反而适得其反,会成比例的增加训练成本,而回报极小。
2. 调参后要给模型足够的训练时间
给模型一点时间,要根据任务难度留给模型一定的学习时间,不能说前面一段时间没起色就放弃了。有些情况下就是前面一段时间看不出起色,然后开始稳定学习。
3. 不要只观察准确率
准确率虽然是评测指标,但是训练过程中还是要注意loss的。你会发现有些情况下,准确率是突变的,原来一直是0,可能保持上千迭代,然后突然变1。而loss是不会有这么诡异的情况发生的,毕竟优化目标是loss。
三、调参
1. 调哪些参数?
学习率,网络层数,每层的结点数,batch_size,剪枝率,动量因子,训练的轮数,学习率衰减率,优化器,正则化系数等等。
2. 怎样去调这些参数?
画图是一个很好的习惯,一般是训练数据遍历一轮以后,就输出一下训练集和验证集准确率。同时画到一张图上。通过观察loss和评价指标的变化来调参。
3. 调学习率
学习率一般是从较小的值开始尝试,常见的学习率为(0.0001,0.0005,0.001,0.002,0.005,0.01)。学习率一般倾向于小一点,但是如果对于的大数据,一般需要要把学习率调到很小,0.00001都不为过。如果在验证集上性能不再增加就让学习率降低(乘以0.9,或者除以2或5),然后继续,学习率会一直变得很小,到最后就可以停止训练了;学习率太大:loss的值会很大,或者为nan。太小: 很长时间loss的值不会有变化。
低的learning_rate曲线会趋近于线性,过高的learning_rate曲线会趋近于指数,高的学习率会使得曲线迅速下降,但是可能会在一个不好的结果下收敛。过高的学习率甚至会使得结果往差的方向发展损失函数突然上升(可能由梯度突然上升引起)。
4. 调batch_size
曲线的震幅反映了batch_size选择的合理程度,一般batch_size大的话曲线会变得更加平滑,也就是说训练的参数和实际的参数拟合度更高。当曲线振幅较大,我们可以在内存和显存允许的范围内,适当增加batch_size来平滑准确率曲线。我们用的随机梯度下降是建立在batch基础上的,合适的batch_size对你模型的优化是比较重要的,这个参数倒不需要微调,在一个大致数量即可,batch_size太大,一般不会对结果有太大的影响,而batch_size太小的话,结果有可能很差。由于无论是多核CPU还是GPU加速,内存管理仍然以字节为基本单元做硬件优化,因此将参数设定为2的指数倍,如16,24,32,64,128等,将有效提高矩阵分片、张量计算等操作的硬件处理效率。
当数据量过大时,往往需要使用较大的batch_size,比如Alibaba在DIN模型的训练时,在自身数据集直接使用了5000的batch_size
5. 调epoch
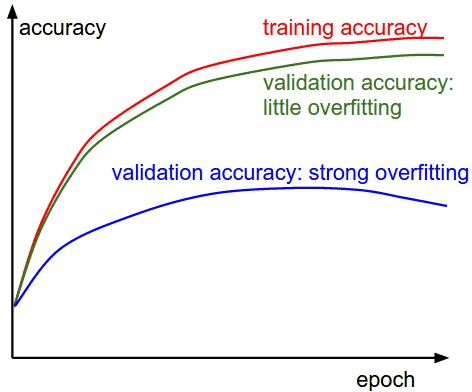
蓝色的曲线显示出验证准确率和训练准确率差别较大,说明可能出现过拟合现象,这种情况可以通过增加正则化项的惩罚系数,或者增加训练样本大小。
-
过拟合:表现形式:训练集准确率较高,测试集准确率比较低
-
解决办法:增加数据、数据增强、参数范数惩罚L1、L2、提前终止、增加dropout值、BatchNormalization
绿色曲线显示出验证准确率和训练准确率差别较小,说明可能训练模型过小,可以适当增加网络的参数。
-
欠拟合:表现形式:训练集,测试集准确率都很低
-
解决办法:增加网络层数,增加节点数,减少dropout值,减少L2正则值等等
epoch应该要和模型表现搭配,如果你的模型已经过拟合了,你就没必要继续跑了;相反,如果epoch太小,epoch跑完了,模型的loss还在下降,模型还在优化,那么这个epoch就太小了,应该增加。
6. 调参策略
从粗到细分阶段调参
实践中,一般先进行初步范围搜索,然后根据好结果出现的地方,再缩小范围进行更精细的搜索。建议先参考相关论文,以论文中给出的参数作为初始参数。至少论文中的参数,是个不差的结果。如果找不到参考,那么只能自己尝试了。可以先从比较重要,对实验结果影响比较大的参数开始,同时固定其他参数,得到一个差不多的结果以后,在这个结果的基础上,再调其他参数。例如学习率一般就比正则值,dropout值重要的话,学习率设置的不合适,不仅结果可能变差,模型甚至会无法收敛。如果实在找不到一组参数,可以让模型收敛。那么就需要检查,是不是其他地方出了问题,例如模型实现,数据。
提高速度
调参只是为了寻找合适的参数,而不是产出最终模型。一般在小数据集上合适的参数,在大数据集上效果也不会太差。因此可以尝试对数据进行精简,以提高速度,在有限的时间内可以尝试更多参数。对训练数据进行采样。例如原来100W条数据,先采样成1W,进行实验看看。减少训练类别。例如手写数字识别任务,原来是10个类别,那么我们可以先在2个类别上训练,看看结果如何。
Random_research
得到所有候选参数,然后每次从中随机选择进行训练。分阶段从粗(较大超参数范围训练较少周期)到细(较小超参数范围训练较长周期)进行搜索。
7. 其他方法
批正则化技术,dropout技术,权重衰减
目前对于是否使用dropout,业界也一直有争论,尤其是非图片但使用embedding的场景,随机丢弃可能并不会带来预期的效果,建议一定要对比使用。
四、注意
- 调参看验证集。train set loss通常能够一直降低,但validation set loss在经过一段降低期后会开始逐渐上升,此时模型开始在训练集上过拟合。
- 优先调参学习率。
- 通过对模型预测结果,可以判断模型的学习程度,如果softmax输出在0或1边缘说明还不错,如果在0.5边缘说明模型有待提高。
- 调参只是为了寻找合适的参数。一般在小数据集上合适的参数,在大数据集上效果也不会太差。因此可以尝试采样部分数据集,以提高速度,在有限的时间内可以尝试更多参数。
参考
https://blog.csdn.net/pwtd_huran/article/details/80882835 https://blog.csdn.net/qq_16234613/article/details/79596609